Abstract
This paper introduces MultiBooth, a novel and efficient technique for multi-concept customization in image generation from text. Despite the significant advancements in customized generation methods, particularly with the success of diffusion models, existing methods often struggle with multi-concept scenarios due to low concept fidelity and high inference cost. MultiBooth addresses these issues by dividing the multi-concept generation process into two phases: a single-concept learning phase and a multi-concept integration phase. During the single-concept learning phase, we employ a multi-modal image encoder and an efficient concept encoding technique to learn a concise and discriminative representation for each concept. In the multi-concept integration phase, we use bounding boxes to define the generation area for each concept within the cross-attention map. This method enables the creation of individual concepts within their specified regions, thereby facilitating the formation of multi-concept images. This strategy not only improves concept fidelity but also reduces additional inference cost. MultiBooth surpasses various baselines in both qualitative and quantitative evaluations, showcasing its superior performance and computational efficiency.
Approach
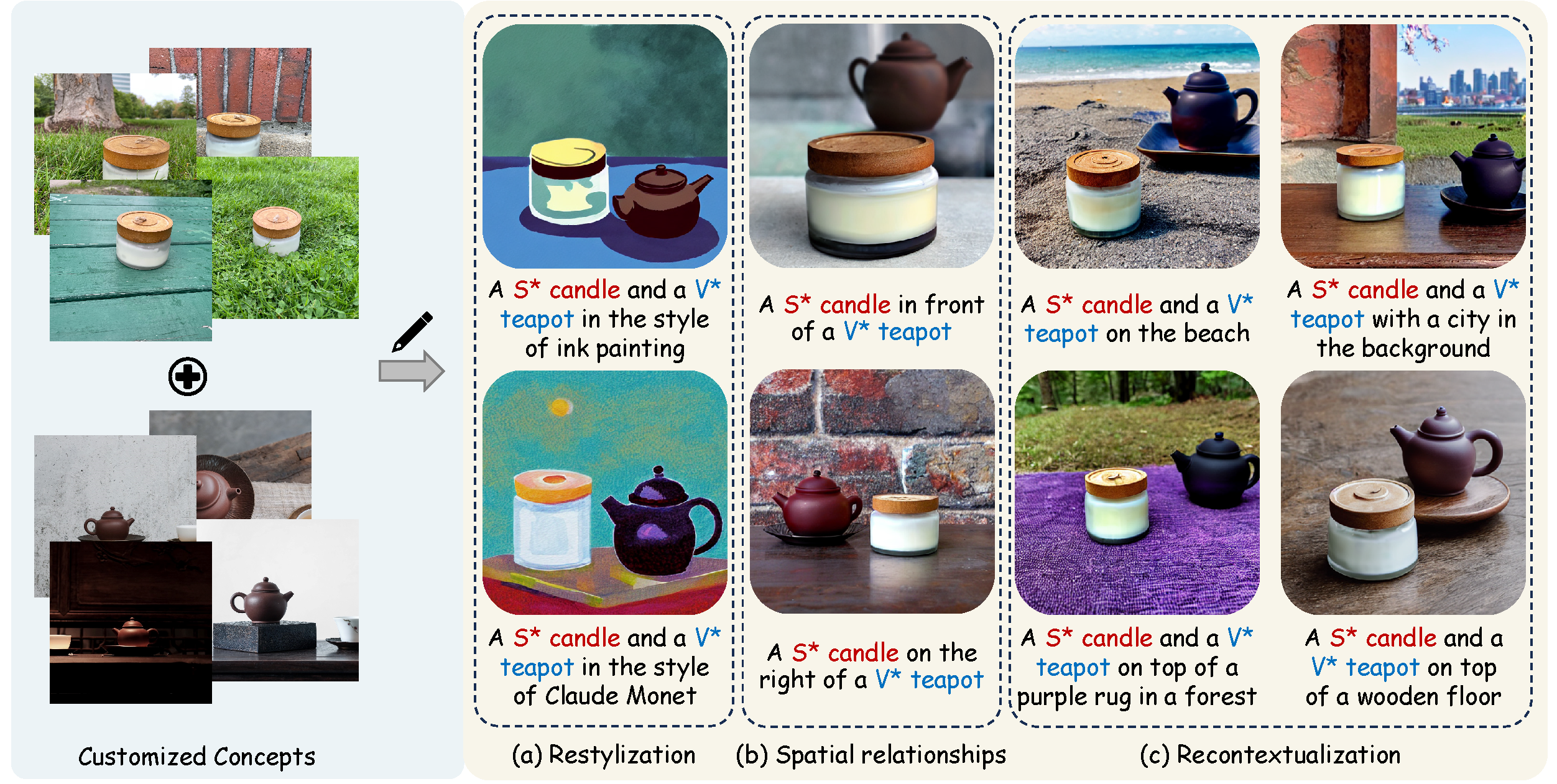
Given a series of images that represent some concepts of interest, the goal of multi-concept customization (MCC) is to generate images that include any number of concepts in various styles, contexts, layout relationship as specified by given text prompts.
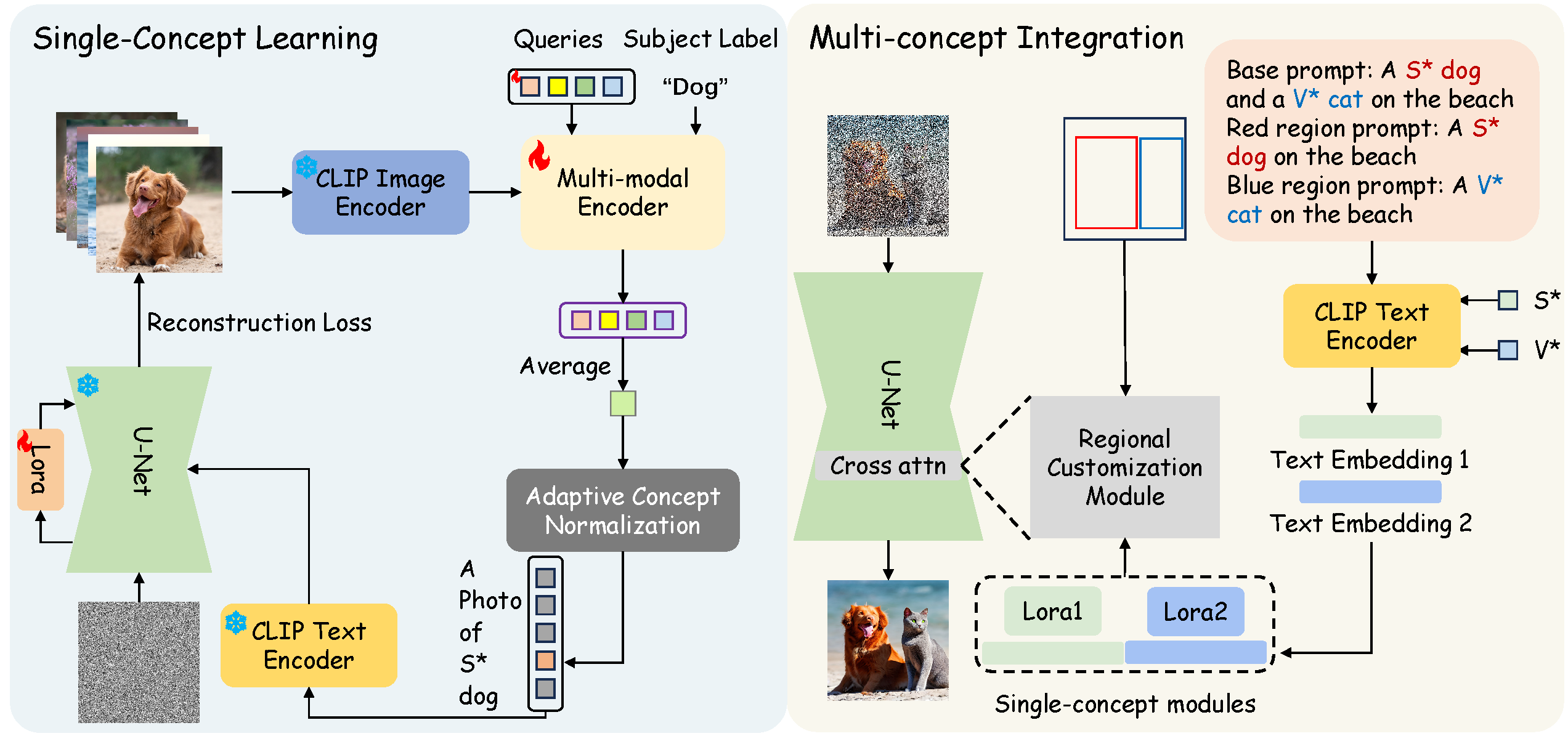
The overall pipeline of MultiBooth can be divided into two phases: (a) During the single-concept learning phase, a multi-modal encoder and LoRA parameters are trained to encode every single concept. (b) During the multi-concept integration phase, the customized embeddings S* and V* are converted into text embeddings, which are then combined with the corresponding LoRA parameters to form single-concept modules. These single-concept modules, along with the bounding boxes, are intended to serve as input for the regional customization module.
Results
Here we demonstrate the customized images generated by different methods. We qualitatively compare our approach with the most recent open-sourced state-of-the-art customization methods, including Textual Inversion, DreamBooth, Custom Diffusion and Cones2.
Ablation Study
We visualize the impact of removing specific components from our framework individually to demonstrate the importance of these methods.

BibTeX
Citation entry for the MultiBooth paper.
@misc{zhu2024multibooth,
title={MultiBooth: Towards Generating All Your Concepts in an Image from Text},
author={Chenyang Zhu and Kai Li and Yue Ma and Chunming He and Xiu Li},
year={2024},
eprint={2404.14239},
archivePrefix={arXiv},
primaryClass={cs.CV}
}